The original version of this post was published as a Twitter thread on March 23rd 2020. I figured I should give it a more permanent home here since IMHO it was a quite fun story.
Since everyone can use some entertainment right now, how about a battle story on how a year ago I spent almost two weeks trying to wrap my head around a really weird issue of a lagging GCODE viewer and overall print progress reporting in OctoPrint and finally figuring it out?
Our story begins around the release of 1.4.0, when a new topic on the community forum showed up:
Curious issue with print progress
The print progress figures on my Octopi setup are lagging behind the actual print. […] Nothing is broken - anything I throw at it (an Ender 3) prints fine but as a print progresses, the percentage complete, current layer, and sync’d gcode viewer gradually lag behind what is actually being printed. For example, on a print with 400 layers, as the last layer is printed the reported progress and current layer is around 96% and 385 respectively. If I do a quick calculation of the displayed Printed/Total file size figures it works out at 96% but what it has actually printed is over 99%. When the print finishes the numbers jump to 100% and 400 and everything is fine.
[…]
This was indeed a very curious issue, since due to the nature of the communication with the printer and buffering in the firmware the progress is usually rather slightly ahead than behind. Some quick testing on my end showed no reproduction, however more and more people chimed in with the same observation.
I was stumped.
My first approach was to collect information from those affected by it. Printer model, firmware version, installed plugins, used slicer and so on. It soon turned out that all affected installations were using Ultimaker Cura as the slicer.
A quick test by the OP with a different slicer confirmed that it indeed just occurred with GCODE sliced by Cura for him, same file in another slicer had everything work as designed. However, comparing the GCODE revealed no immediate differences that would explain this, and what actually is in the file also doesn’t really play into progress tracking. My own experiments with Cura failed to reproduce.
Convinced that the issue must be some sort of delay between the backend and the frontend – maybe due to network issues? – I whipped up a plugin (since deleted) to log progress on both ends to a log which could then be shared and analysed. The first results came in an guess what? I had barked up the wrong tree, the reported progress was identical. So back to square one.
I still couldn’t reproduce it on my end and was starting to get really angry at this issue 😅 I finally threw a copy of some GCODE files now shared by the reporter of the issue on my own printer and finally I could reproduce. Which doesn’t mean I had any idea WTF was going on though.
After many test prints, head scratching and going through the files with a comb I finally noticed something. The files with the issue had CRLF (or \r\n) line endings. Those without (including my own sliced files) had just LF (or \n) line endings.
So that made me go 🤨 Some cursing and breakpoint setting later I had proof that the reported progress in backend and frontend was flawed to begin with. I could see that a line was being reported with a file position that it actually was not located at in the file, and which instead belonged to a couple lines earlier. Which meant my positions were reported wrong right at the source – with a lag. And then it suddenly hit me.
But before I can tell you what was happening I need to give you some background on how OctoPrint reads GCODE files it’s printing in order to understand what was going on. Printed files are read line by line because that is how they are sent to the printer. For that OctoPrint uses the readline method of the file stream. And that works by reading chunks of data from the file until a line separator is found, returning everything read up to this separator and saving the rest for the next line to be read. That means the file will have to be read further than what is returned. And that means that the position in the open file as reported by tell on the file stream will always be slightly ahead. For progress reporting in OctoPrint however I need to know the exact byte position of each line in the file. So what I do instead of relying on the internal and slightly ahead file position is that I increase my own position indicator by the length of the line read from the file. And this is where my problem was located.
It turns out that for some reason I wasn’t getting the lines back from readline with the original line endings attached. Instead I always got LF, even for files with CRLF. And that means I was counting one byte short for every single line in CRLF terminated files. One byte short per line doesn’t sound like much, but that adds up through a file with several hundred thousands of lines, to a point where progress reporting will be off by whole layers the further in the print and thus the file you are.
But what was the reason for this popping up in 1.4.0? I hadn’t modified the code in question at all. It had been the same since 2016 actually. Well, it turns out that a tiny change during the Python 3 compatibility migration done to a helper function I used in that code had interesting side effects: switching from codecs.open to io.open.
It turns out that io.open (and thus Python 3’s built-in open) by default will open text files in “universal newlines mode” (see PEP278), meaning it will happily parse every common line ending, but convert it to LF before returning. Which caused my off-by-one issue in files with CRLF.
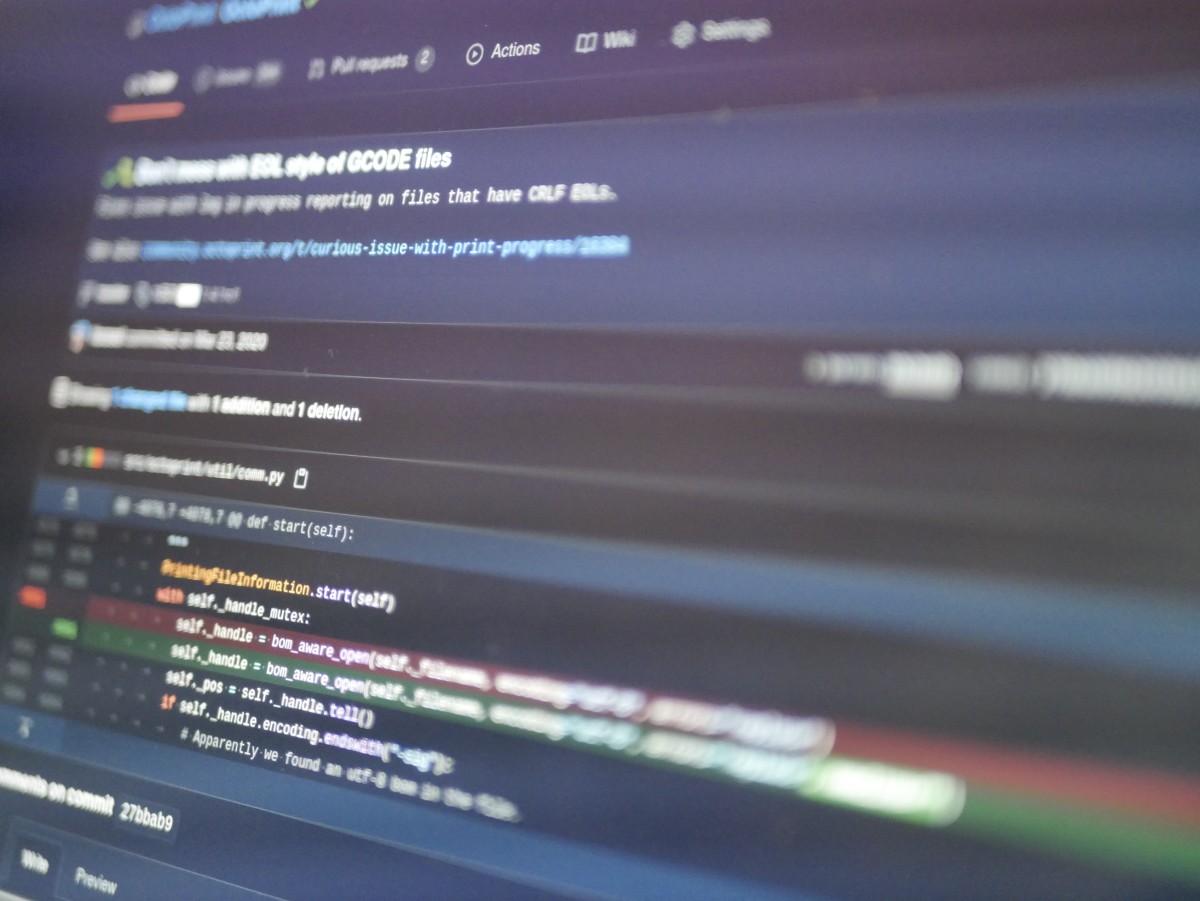
And the fix? Setting newline="" on the open call:
diff --git a/src/octoprint/util/comm.py b/src/octoprint/util/comm.py
index 67191a7af..a6dfc1e24 100644
--- a/src/octoprint/util/comm.py
+++ b/src/octoprint/util/comm.py
@@ -4078,7 +4078,7 @@ def start(self):
"""
PrintingFileInformation.start(self)
with self._handle_mutex:
- self._handle = bom_aware_open(self._filename, encoding="utf-8", errors="replace")
+ self._handle = bom_aware_open(self._filename, encoding="utf-8", errors="replace", newline="")
self._pos = self._handle.tell()
if self._handle.encoding.endswith("-sig"):
# Apparently we found an utf-8 bom in the file.
The moral of the story? Don’t trust your file position calculations. I could have saved myself a lot of time on debugging this if I had just looked there first instead of assuming this code to be fine 😅
In the end, even a year later, I still have no idea why Cura produced CRLF code for some and LF for me, but I also never really looked hard. A UNIX vs Windows issue can be ruled out here since the affected parties and me were all using Windows. It made me learn something about io.open and was a valuable lesson on wrong assumptions however!